- Refuting AWS Chain Attack - Digging Deeper into EKS Zero Day claims
- Attack 1 - Utilizing the metadata service on the EKS Worker Node to access temporary credentials
- Attack 2 - Generating a new kubeconfig
- Risks with the described “attacks”
- Conclusion
Refuting AWS Chain Attack - Digging Deeper into EKS Zero Day claims
This post is an analysis of the findings published by a security researcher last month about two zero days in AWS EKS that the researcher claimed to affect thousands of vulnerable EKS clusters. You can read the article here.
This post is an analysis post, meant to simplify and dig deeper into the findings published in the original post. We re-created the environment described in the post and concluded that the original post misses considerable detail when talking about default AWS EKS clusters and amplifies the risk that the setup presents.
The Claims
The researcher claims that AWS EKS in its default configuration, without any third party security products is vulnerable to 2 zero days
- Utilizing the metadata service on an EKS worker node to generate a token and using the token to generate API requests to get access to the EC2 Role.
- Using the EKS cluster IAM role to generate a kubeconfig that can then be used to start new containers and escape to the underlying node/lateral movement to other containers.
We will take a look at the default configuration for both these scenarios and examine the cluster configuration, the actual permissions and EKS documentation to draw our conclusions.
Attack 1 - Utilizing the metadata service on the EKS Worker Node to access temporary credentials
When setting up a cluster in AWS EKS, there are two IAM roles involved. These are required so that the Kubernetes clusters (which are managed by AWS) can make calls to and work with other AWS servics on your behalf to manage the resources that you use with the service. This is true for all services within AWS. Just like how EC2 that interacts with S3 will require an IAM role with S3 capabilities to be attached to it.
The AWS EKS cluster IAM role and EKS Worker node are well documented, along with the actual permissions within each role. By looking at the permissions, we know what capabilities the cluster and nodes will have.
- AWS EKS Cluster IAM Role - https://docs.aws.amazon.com/eks/latest/userguide/service_IAM_role.html
- AWS EKS Worker Node IAM Role - https://docs.aws.amazon.com/eks/latest/userguide/create-node-role.html
If an attacker manages to gain access to a pod (SSRF, code exec, stolen kubeconfig, SSH to pod etc.) and has exec capabilities, they would be able to access the Instance metadata endpoint and generate temporary credentials. This is expected behavior as the Pod Network can reach the Node’s IMDS endpoint.
Since the Node is an EC2 instance at the end of the day, IMDS can be v1, v2 or disabled. The researcher’s article points to the nodes running IMDSv2, which requires a token to pull any meaningful data from the IMDS endpoint.
Here’s a documented way to do this.
TOKEN=`curl -sX PUT "http://169.254.169.254/latest/api/token" -H "X-aws-ec2-metadata-token-ttl-seconds: 21600"` \
&& curl -sH "X-aws-ec2-metadata-token: $TOKEN" http://169.254.169.254/latest/meta-data/
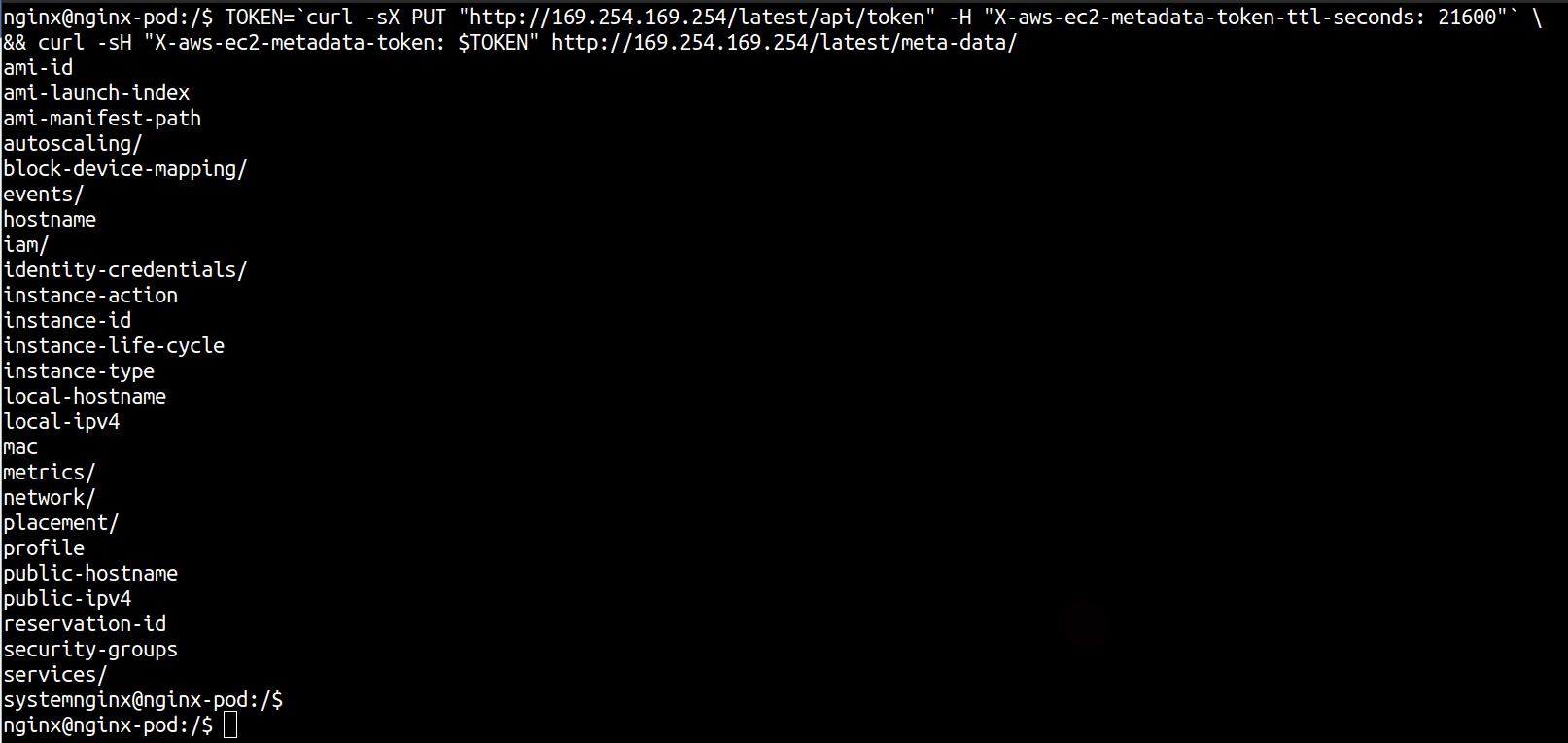
The researcher created a custom script to make requests to IMDS. The original article states
“The script works by first retrieving the mac addresses of the nodes-instances, and then generating a request for information based on the mac address. This enables the script to retrieve information on the relevant subnets and security groups, node names, cluster names, cluster host names, and other relevant details.
With this script, it is possible to obtain valuable network information about node instances in a cluster quickly and efficiently, without resorting to time-consuming and potentially intrusive scanning methods.” (sic)
This, of course, makes no sense, as the IMDS endpoint, by design, is accessible only from the machine itself. The endpoint address - 169.254.169.254 is non routable and cannot be reached from outside the nodes. Additionally, there is no “time-consuming and potentially intrusive scanning methods” involved here. Data from IMDS is retrieved via plain old HTTP GET requests (with a session token form IMDSv2 and without for IMDSv1). A simple script generated using ChatGPT can be used to fetch all the data within IMDS quickly.
The author then claims that “To retrieve the EC2 role of a node, you can send a request to the metadata service. By adding the token to the request, you can obtain the privileged role of the instance.
Without the token, we will usually get an unprivileged role.” (sic)
This is factually incorrect. If IMDSv2 is enabled, then requests without a valid token or with an expired token receive a 401 - Unauthorized HTTP error code and you will not get ANY credentials. Also, there is only one privilege level, the level of the attached IAM role to the Node.
Here are the cURL requests to generate temporary credentials from the IMDS endpoint. The first cURL request gets the name of the IAM role attached to the EKS Node while second cURL uses the role name to fetch temporary credentials internally using STS Assume-Role operation.
ROLENAME=`curl -sH "X-aws-ec2-metadata-token: $TOKEN" http://169.254.169.254/latest/meta-data/iam/security-credentials/`
curl -sH "X-aws-ec2-metadata-token: $TOKEN" http://169.254.169.254/latest/meta-data/iam/security-credentials/$ROLENAME
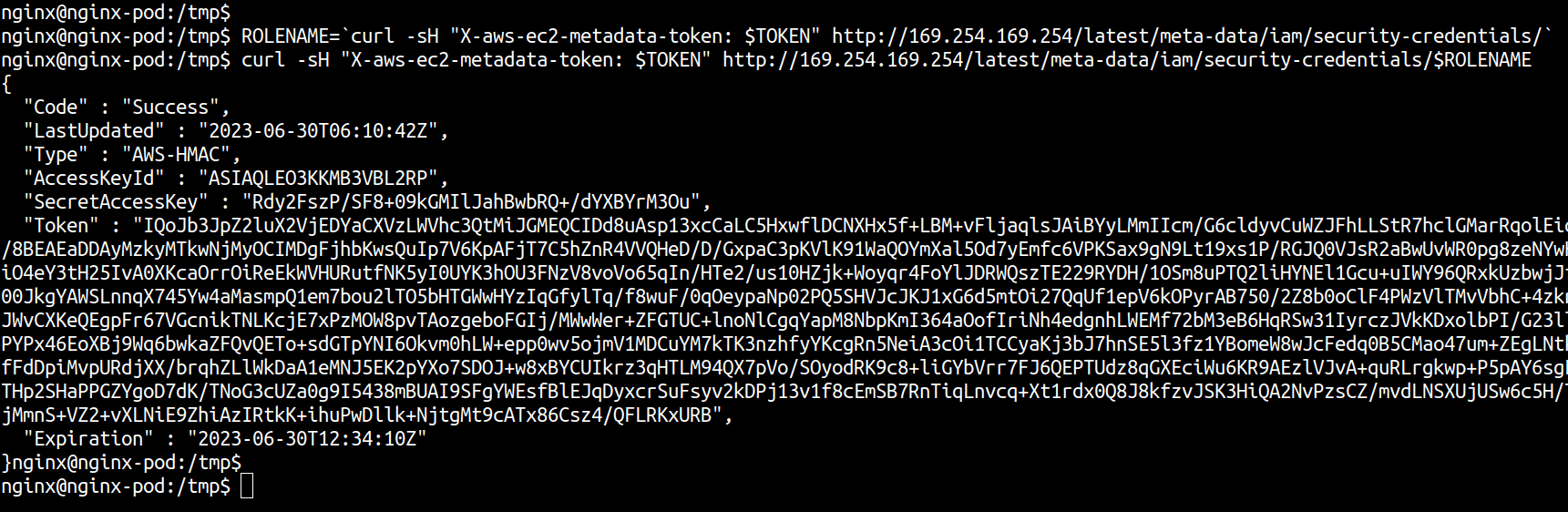
Quickly configuring the credentials locally and checking the identity of the assume role we have the following

This is not a security problem, but a known, well documented design of EC2
The researcher claims that there were limitations on these credentials (could not access databases etc.) and despite these limitations they were able to “bypass” these by utilizing the “Describe-Tags” functionality. This is, again, not a bypass, but a property of the default permissions of this attached role. The default EKS node IAM role is supposed to have the following IAM policies attached
The ability to run describe-tags is via the AmazonEKS_CNI_Policy attached policy, as seen in the policy description.
Attack 2 - Generating a new kubeconfig
The author begins this section by saying “Despite my default role permissions not including write or list permissions for components or access to cloud components, I was able to discover that the role did have permissions to generate a new “kubeconfig” file. (sic).
This is, again, a property of the permissions of the EKS Node role via the eks:DescribeCluster permission in AmazonEKSWorkerNodePolicy policy attached to this role. Any IAM role can generate kubeconfig for a given cluster if it has the eks:DescribeCluster permission.
The author then claims that “Since the API did not have sufficient RBAC permissions to list namespaces, I had to find a workaround.” (sic), which is incorrect as the kubeconfig that is generated has sufficient permissions to list pods across namespaces but not the namespaces themselves. If a namespace does not have a pod running, it is inconsequential to the attack approach.
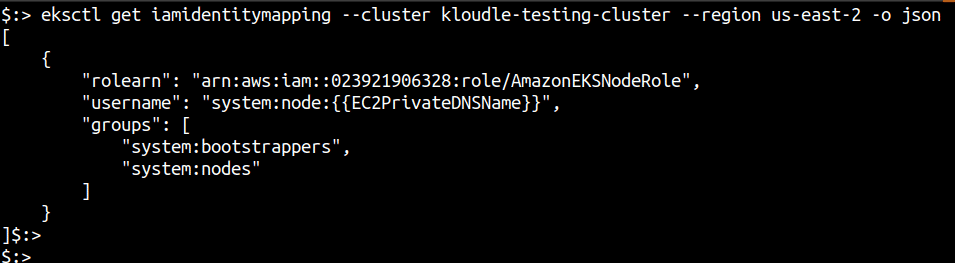
You can verify the IAM Identity mapping between the Node IAM role and the cluster using eksctl.
eksctl get iamidentitymapping --cluster <CLUSTER_NAME> --region <REGION> -o json
Here’s what it looks for my cluster. You can see that the role (and consequentially any credentials generated via AssumeRole) will work as a user in the “system:nodes” special Kubernetes group, which by design will have Read permissions for services, endpoints, nodes, pods, secrets, configmaps, PVCs and PVs related to pods bound to the kubelet’s node.
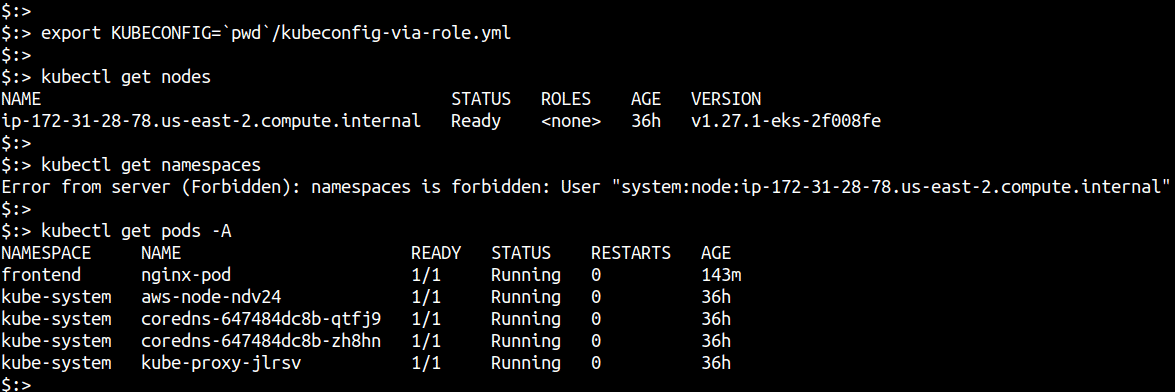
To list all pods across all namespaces run kubectl get pods -A
Risks with the described “attacks”
The last section of the researcher’s article describe the apparent risk due to the attacks. Both the described attacks are in fact well known and documented by AWS and Kubernetes, as seen above. The researcher ends the article talking about potential risks associated with the execution of the attacks.
There are 3 “risks” covered
- Exposure of K8’s namespace manifest, which contains details about its integration with services, databases, environment variables, etc.
- Exec to pods -Due to integrated systems that very common and essential, such as monitoring and backup systems like Prisma, it is common to grant the role permission to exec, which results in the takeover of every namespace in the pod.
- Takeover via vulnerable pod deployment- depends on the RBAC.
(sic)
Exposure of Kubernetes namespace manifest
The manifest that the researcher is talking about here is the -o yaml output of a get pod operation. As we have seen, this is not a security problem but it is how the system:nodes group gives the current IAM role the ability to list pods. Adding a -o yaml simply provides a more detailed output of the pod
kubectl get pods -A
kubectl get pod podname -n namespace -o yaml
Exec to pods
This section vaguely describes how a YAML (missing in the text) can be used to achieve connection to the pods.
The default Node Authorizer has the ability to only create “mirror” pods. Mirror pods in Kubernetes are a special type of pod used for debugging and troubleshooting purposes for static pods. They are automatically created by the kubelet on each node in the cluster when a static pod yaml is encountered on the node specified by directory in kubelet --pod-manifest-path=<directory> or the HTTP path in kubelet --manifest-url=http://path/of/pd/yaml, in the startup arguments.
Although kubectl auth can-i create pods shows `yest, an attempt to create a standard pod, using the Node Authorizer kubeconfig, will throw an error as shown below.

The Node Authorizer can only create mirror pods to static pods that are running on the system. However, running kubectl debug to start debug pods also results in an error since the system:nodes group does not have the ability to patch running containers.

Based on the claim - ‘By setting the “mirror” field in the pod’s annotations to “true”. This allow us to gain access to the target node and ultimately the pods.’ (sic) - I created the following pod yaml to satisfy the Node Authorizer’s requirement for the missing "kubernetes.io/config.mirror" annotation (set to true), spec.nodeName set to the name of the node, an owner reference set to itself and a controller owner reference set to true, which still resulted in the pod creation to fail.
apiVersion: v1
kind: Pod
metadata:
name: ubuntu-mirror-pod
namespace: frontend
ownerReferences:
- apiVersion: v1
kind: Node
name: ip-172-31-28-78.us-east-2.compute.internal
controller: true
uid: e730a0ca-5bde-41d0-be12-9a8baefc4eea
annotations:
kubernetes.io/config.mirror: "true"
spec:
nodeName: ip-172-31-28-78.us-east-2.compute.internal
nodeSelector:
kubernetes.io/hostname: ip-172-31-28-78.us-east-2.compute.internal
containers:
- name: ubuntu-container
image: ubuntu
command: ["/bin/sleep", "infinity"]
Creating a vulnerable container for takeover
This section is titled incorrectly. The section describes an image called vulnpod created from a debian image with SSHd configured. Running a pod from this image should provide the ability to SSH into it. This is being done as the Node Authorizer does not have exec permissions to new attacker pods created with volume mounts pointing to the docker socket on the node (assuming the previous section worked).
The image is built locally and hosted on a local docker registry using these commands
docker build -t vulnpod:v2 .
docker run -d -p 5000:5000 -restart=always -name registry registry:2
docker tag vulnpod:v2 localhost:5000/vulnpod:v2
docker push localhost:5000/vulnpod:v2
docker image ls localhost:5000/vulnpod:v2
The researcher’s final claim in this section is that once the local registry is hosting our image, we can use the following pod yaml to run the pod and SSH to it.
apiVersion: v1
kind: Pod
metadata:
name: vulnerable-mirror-pod
namespace: ui-systems
spec:
nodeName: e730a0ca-5bde-41d0-be12-9a8baefc4eea
nodeSelector:
kubernetes.io/hostname: ip-172-31-28-78.us-east-2.compute.internal
containers:
- name: vulnerable-mirror-pod
image: localhost:5000/vulnpod:v2
volumeMounts:
- name: docker-sock
mountPath: /var/run/docker.sock
securityContext:
privileged: true
ports:
- containerPort: 22
env:
- name: MY_ENV_VAR
value: "my_value"
volumes:
- name: docker-sock
hostPath:
path: /var/run/docker.sock
This, of course, does not work as we know the Node Authorizer can only create mirror nodes (and the other conditions we saw earlier). Even after updating the yaml with ownerReferences and corrected mirror annotations, the yaml did not yield a running pod that could be SSHd to, as the article claims.
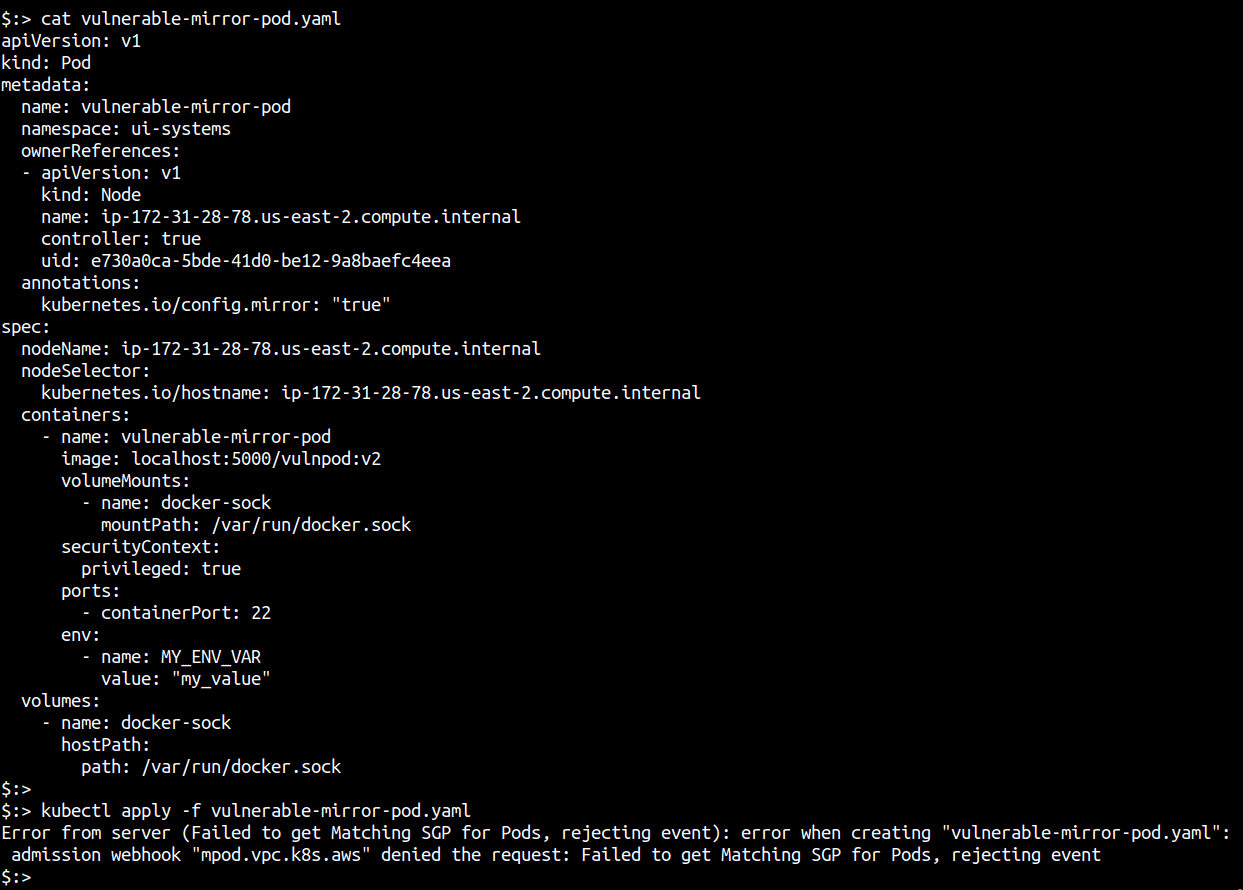
The article is vague after this point (including an incorrect copy command and a chroot command that points to a volume mount that was never a part of the pod yaml!!).
Conclusion
Careful examination of the claims made in the blogpost show that the author’s discovery of various attacks and responses are in fact the way AWS EKS and Kubernetes have been designed to work. At no point in the article, any evidence of an actual zero day or a vulnerability was presented that could not be dismissed.
The researcher’s blogpost is more a self learning and discovery post about the working of AWS EKS and Kubernetes, rather than disclosure of actual vulnerabilities that affect thousands of AWS EKS clusters (as claimed). It is recommended to ensure security best practices are followed anyways for cluster resources, using authorization and inbuilt security controls that AWS EKS provides.
Until next time, Happy Hacking!!

Riyaz Walikar
Founder & Chief of R&D
Riyaz is the founder and Chief of R&D at Kloudle, where he hunts for cloud misconfigurations so developers don’t have to. With over 15 years of experience breaking into systems, he’s led offensive security at PwC and product security across APAC for Citrix. Riyaz created the Kubernetes security testing methodology at Appsecco, blending frameworks like MITRE ATT&CK, OWASP, and PTES. He’s passionate about teaching people how to hack—and how to stay secure.
Riyaz Walikar
Founder & Chief of R&D
Riyaz is the founder and Chief of R&D at Kloudle, where he hunts for cloud misconfigurations so developers don’t have to. With over 15 years of experience breaking into systems, he’s led offensive security at PwC and product security across APAC for Citrix. Riyaz created the Kubernetes security testing methodology at Appsecco, blending frameworks like MITRE ATT&CK, OWASP, and PTES. He’s passionate about teaching people how to hack—and how to stay secure.