Introduction
AWS S3 or Amazon Simple Storage Service is a very popular service in the cloud computing industry that is used to store objects on the cloud which can be accessed and made available by the service administrators, anywhere at any time. Amazon S3 can store any type of object. It allows uses like storage for Internet applications, backups, disaster recovery, data archives, data lakes for analytics, and hybrid cloud storage. Organizations use S3 as a standard file store, as Content Delivery Network backends, for static site hosting, to take backup of file systems, compute instances, databases, code bases and much more.
When all sorts of data ends up on a third party provider, AWS S3 in our case here, as owners of the data, we need to be prudent and ensure that all security features that AWS provides are enabled or configured to ensure maximum security.
To ensure data security, the following questions about the storage, access and audit need to be answered
- What data that I own or am responsible for, can be considered sensitive?
- How does a trusted and authorized entity know this data is sensitive?
- How do I ensure only authorized users or applications and services can access this data?
- How do I ensure that my data is encrypted at rest and in motion?
- How do I perform logging and monitoring of this data, to audit for access and operations?
- How do I recover this data if there is an unintended or unauthorized modification?
Let’s answer these questions one by one, while utilizing the features and capabilities of AWS S3.
What is sensitive data?
For data to be deemed sensitive, one must understand the context in which the data is produced, stored and used. Most definitions of “sensitive data” enforce the idea of privileged access and access gates. In addition to this, one must also take into account in which contexts the data becomes sensitive. For example, the first name of an individual is not considered to be sensitive information in isolation unless combined with additional identifying data like phone number, home address, email address, racial or ethnic origins or religious beliefs.
There are a lot of common examples of sensitive data whose unauthorized access could lead to significant business impact that includes not only regulatory fines but also loss in user trust. Here are some broad classifications:
Protected Health Information (PHI) - One of the more recognized classifications of sensitive information as defined by the Health Insurance Portability and Accountability Act of 1996 (HIPAA). PHI under the US law is any information about a specific individual’s health status, access to or payment for health care that is created or collected by a Covered Entity (or a third-party associate).
Customer Information - For an organization, this could be information about their customers, app statistics, usage behavior, metadata about the customer’s infrastructure or secondary customers and billing information including credit card data as defined by the Payment Card Industry Data Security Standard (PCI DSS).
Trade secrets and intellectual property - This is data created, maintained and used internally by an organization, and which is used to create the organization’s product or service offerings. Examples of this include infrastructure plans, network diagrams, encryption keys, source code, passwords, and account information.
Tagging and data classification
Regardless of the type of data, in environments where multiple authorized users may have access to AWS S3, it is important to tag data. In AWS S3, you can use the S3 Bucket’s tagging feature to create relevant tagging information as agreed upon and understood by the business, infrastructure and development teams. More often than not, Ops teams tag buckets based on whether they contain “production”, “staging” or “test” data. This nomenclature can be extended to include the types of data as well. You can even tag individual objects within an S3 bucket for granular classification.
To get started with this in AWS S3, navigate to the bucket containing your data that needs to be tagged and click on the Properties tab
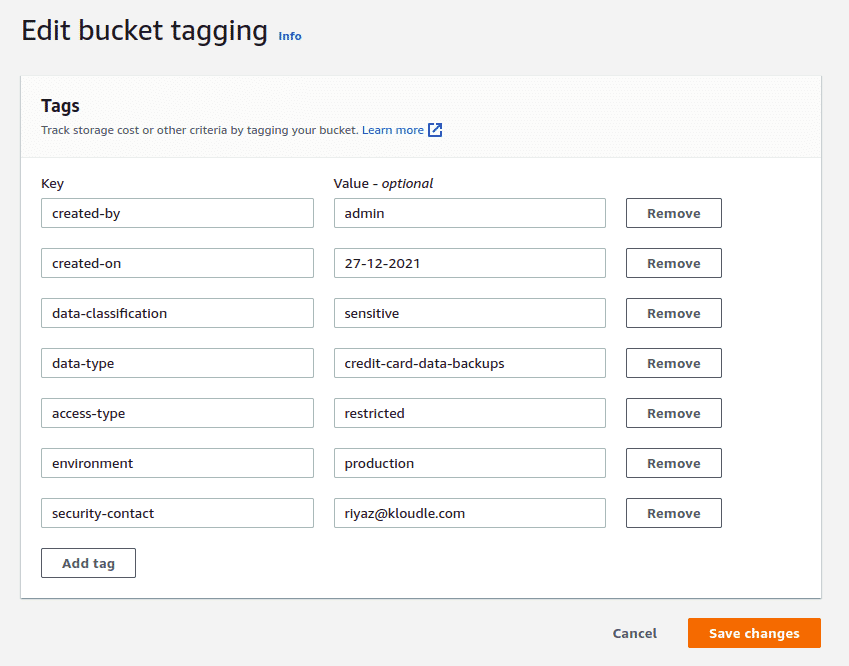
Click on Edit under Tags and add appropriate tags in the “Edit bucket tagging” window. Here’s an example of some tags that you could use in your infrastructure.
Click on Edit under Tags and add appropriate tags in the “Edit bucket tagging” window. Here’s an example of some tags that you could use in your infrastructure.
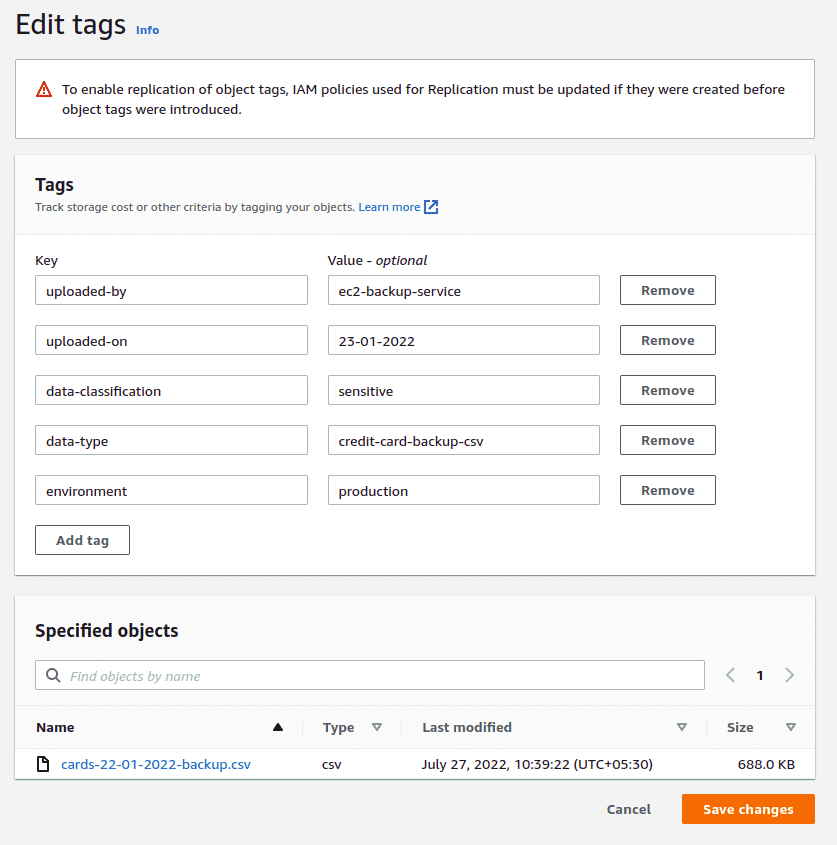
To add tags to individual objects, navigate to the object in the bucket, scroll down and click on the Edit button in the “Tags” section to add any additional object specific tags you have.
To add tags to individual objects, navigate to the object in the bucket, scroll down and click on the Edit button in the “Tags” section to add any additional object specific tags you have.
AWS S3 Bucket Policies and Public Access
One of the more common ways of restricting Internet wide access, as well as AWS IAM user level restriction is to apply bucket policies and to disable public access.
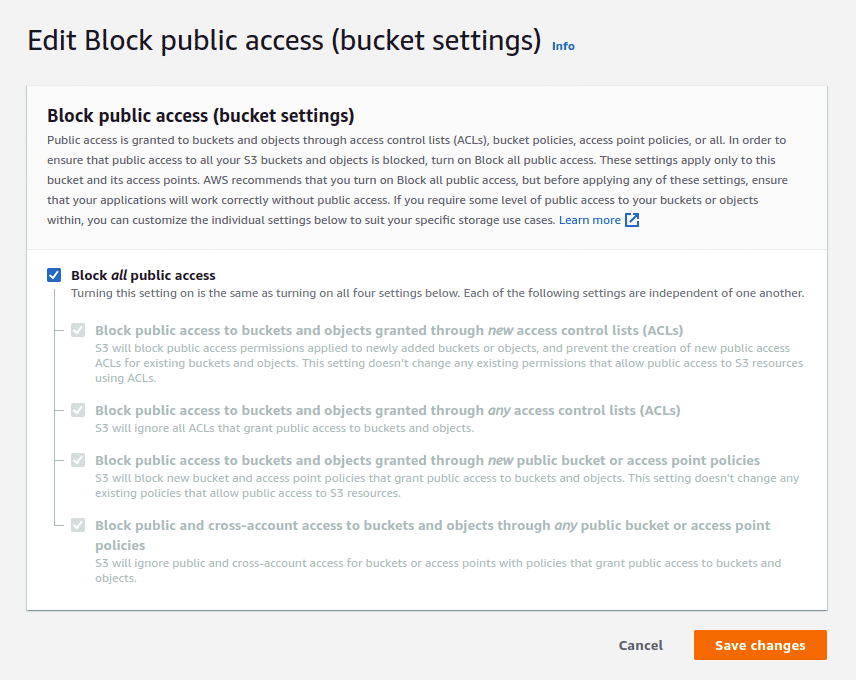
By default, when you now create a new AWS S3 bucket, the Block Public Access property is set to On for all new buckets (unless you copy the settings of a bucket that is already public). There are very few reasons why the data in your bucket needs to be exposed to the Internet (static hosting, CDN, public code repos, file hosting are some of them). The “Block all public access” prevents any arbitrary user on the Internet from accessing the contents of the bucket. Ensure that all public access is blocked as sometimes allowing ACLs to be updated but allowing its contents to remain private could allow an attacker to update the bucket’s permissions and escalate their privileges to access the contents of the bucket.
Authorized applications and users use signed URLs, with a set expiration time, to access the contents. To generate a presigned URL to be used with an app or user, navigate to the object in the bucket, click on “Object actions” button and click on “Share with a presigned URL”.
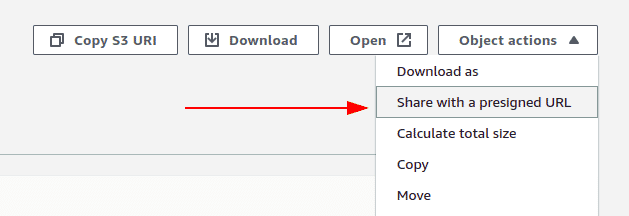
To generate a presigned URL using the command line, you can run the following command
To generate a presigned URL using the command line, you can run the following command
aws s3 presign <S3-Object-URL>

For more granular permissions, you can use AWS S3 bucket policies to restrict access to AWS accounts, IP addresses, User Agents, the actions they can perform (or are disallowed) and on what resources these actions can be performed. For example, the following bucket policy restricts access to the bucket to a single IP address range.

You can block complete Internet access to the bucket and continue to provide access to apps via an IAM role, specifically created to allow READ and limited WRITE to the objects. Under IAM, a role can be assigned the following permission policy to allow for bucket listing and to create objects in the bucket.
You can block complete Internet access to the bucket and continue to provide access to apps via an IAM role, specifically created to allow READ and limited WRITE to the objects. Under IAM, a role can be assigned the following permission policy to allow for bucket listing and to create objects in the bucket.
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "ListObjectsInBucket",
"Effect": "Allow",
"Action": ["s3:ListBucket"],
"Resource": ["arn:aws:s3:::bucket-name"]
},
{
"Sid": "AllObjectActions",
"Effect": "Allow",
"Action":["s3:GetObject","s3:PutObject"],
"Resource": ["arn:aws:s3:::bucket-name/*"]
}
]
}There are numerous tools available that can be used to discover publicly open and accessible S3 buckets on the Internet. Services like GrayhatWarfare search and catalog the contents of these public buckets for search and download.
AWS S3 Encryption
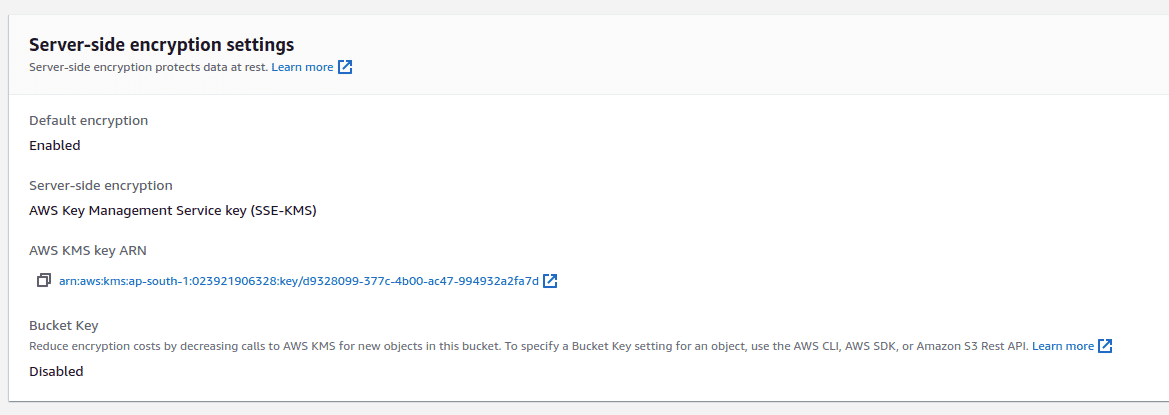
AWS S3 now fully supports server side encryption for new objects that are added to the bucket. However, this needs to be explicitly enabled for the bucket so that you can choose the keys that you would use to encrypt the objects.
With server-side encryption, Amazon S3 encrypts an object before saving it to disk and decrypts it when you download the object. You can set encryption on individual objects within S3, independent of global encryption settings.
When you enable default encryption, you can use Amazon S3 managed keys (SSE-S3) or AWS Key Management Service (AWS KMS) keys (SSE-KMS). If you use SSE-KMS, you can choose a customer managed key or use the default AWS-managed key. Customer managed keys give you more control over your keys, including establishing and maintaining their key policies, rotating their cryptographic material, and more.
To enable server-side encryption for the bucket, click on the “Properties” tab of the bucket, scroll down to find the “Default encryption” section, click on “Edit” to enable encryption.
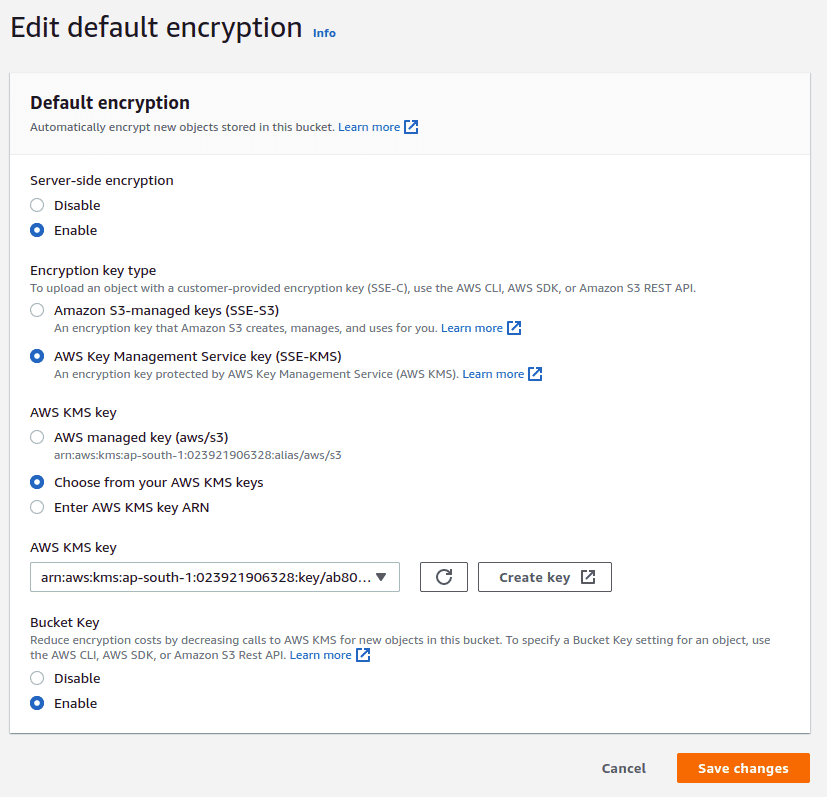
From an AWS CIS Benchmark compliance point of view, it is required to use your own managed key for encryption. This can be chosen by creating a new key under AWS KMS and selecting the key from the drop down in this section for the AWS KMS Key.
From an AWS CIS Benchmark compliance point of view, it is required to use your own managed key for encryption. This can be chosen by creating a new key under AWS KMS and selecting the key from the drop down in this section for the AWS KMS Key.
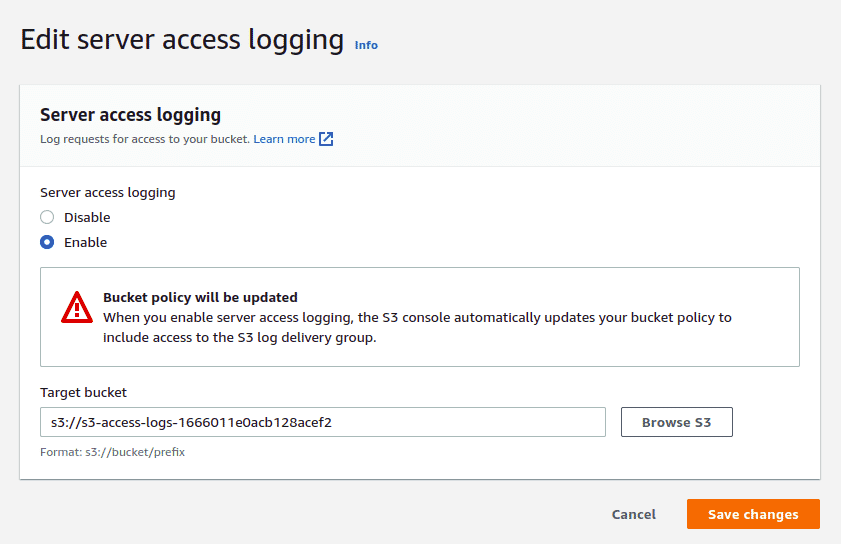
AWS S3 Logging and CloudTrail
Server access logging provides detailed records for the requests that are made to a bucket. You can enable logging under bucket properties and then under “Server access logging”.
Amazon S3 periodically collects access log records, consolidates the records in log files, and then uploads log files to your target bucket as log objects. If you enable logging on multiple source buckets that identify the same target bucket, the target bucket will have access logs for all those source buckets. However, each log object reports access log records for a specific source bucket.
These logs can then be queried and parsed using AWS Athena or locally via a text editor, in the case of unauthorized access or a data breach.
In addition to the standard logging that AWS offers, AWS CloudTrail is also available to be used for log management and data events from S3 and even configured with CloudWatch Alarms to send out notifications in the event of a data breach.
To enable CloudTrail logging, go to the “AWS CloudTrail data events” section under the “Properties” tab and click on the “Configure CloudTrail”. Create a new CloudTrail and ensure that the “Management events” and “Data events”are selected for S3.
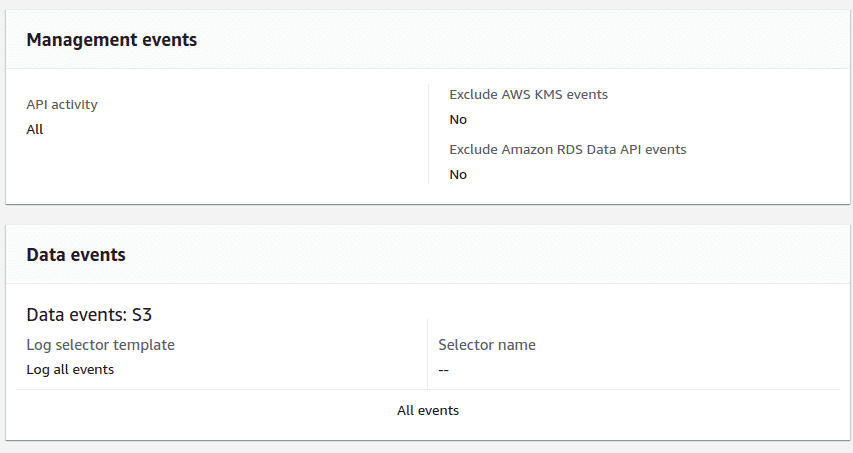
You can use the CloudTrail logs to perform analysis and forensics in the event of a breach by importing the logs to Athena and running queries to identify breach parameters.
You can use the CloudTrail logs to perform analysis and forensics in the event of a breach by importing the logs to Athena and running queries to identify breach parameters.
AWS S3 Object Versioning
AWS S3 supports object versioning. Versioning is a means of keeping multiple variants of an object in the same bucket. You can use versioning to preserve, retrieve, and restore every version of every object stored in your Amazon S3 bucket. Think of this as code commits, you can always go back to an older version if an object was deleted from both unintended user actions and application failures.
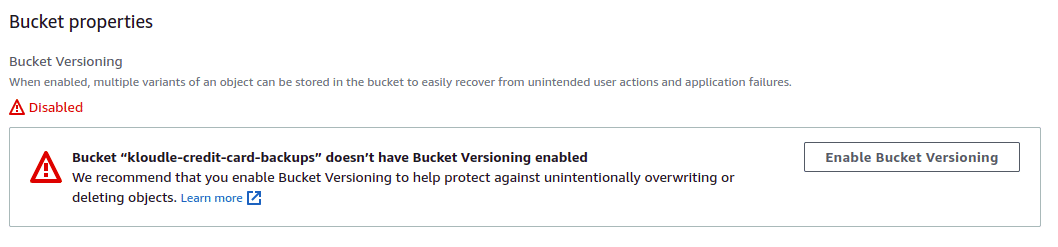
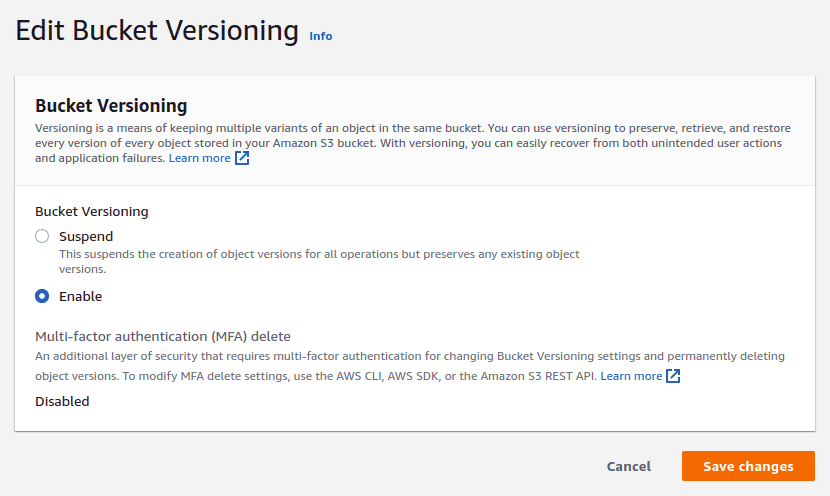
You can enable object versioning by navigating to the “Properties” tab of the bucket, clicking on the “Edit” button for “Bucket Versioning” and then “clicking on Enable”.
You can enable object versioning by navigating to the “Properties” tab of the bucket, clicking on the “Edit” button for “Bucket Versioning” and then “clicking on Enable”.
For every new upload of an object with the same name, a new version will be created and made default. You can view and download older versions of objects by using the “Versions” tab of the object and clicking on the version ID of the object. To make an object as the default version, you can either download and re-upload the object or use the “Copy” or “Move” option to recreate the object as the default version in the same bucket.
For every new upload of an object with the same name, a new version will be created and made default. You can view and download older versions of objects by using the “Versions” tab of the object and clicking on the version ID of the object. To make an object as the default version, you can either download and re-upload the object or use the “Copy” or “Move” option to recreate the object as the default version in the same bucket.
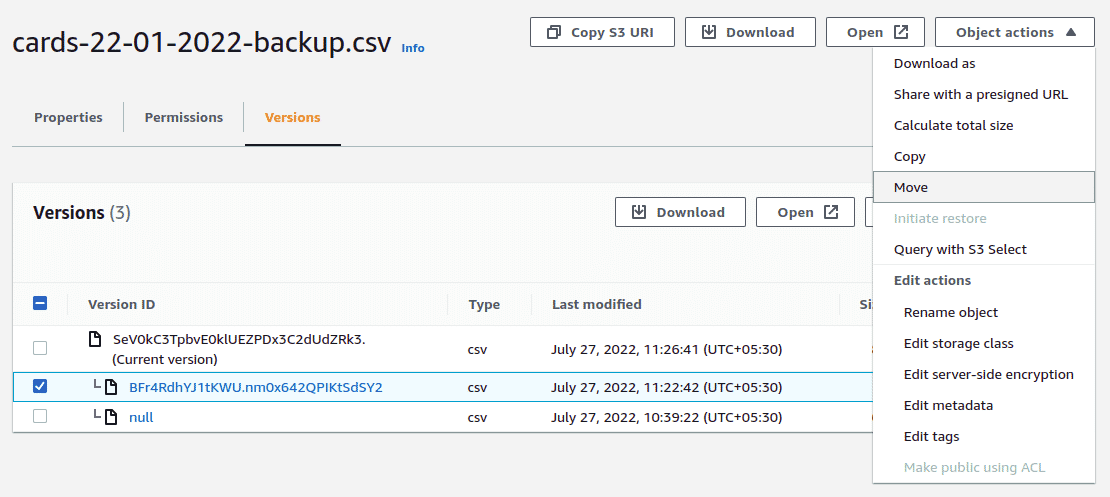
The “Initiate restore” option under “Actions” is used with AWS Glacier, the object long term archival service by AWS.
The “Initiate restore” option under “Actions” is used with AWS Glacier, the object long term archival service by AWS.
Additional Configurations for Security
Two additional configuration options that you can use to further enhance the security of objects within AWS S3 is by
- Enabling the requirement for Multi Factor Authentication to delete objects
- Enabling object locking when creating a new bucket
Multi Factor Authentication to delete objects
To prevent unauthorized or accidental deletion of objects when uploaded to S3, you can add another layer of security by configuring a bucket to enable MFA (multi-factor authentication) delete. When you do this, the bucket owner must include two forms of authentication in any request to delete a version or change the versioning state of the bucket.
Instructions to enable MFA on delete requests can be found here - https://docs.aws.amazon.com/AmazonS3/latest/userguide/MultiFactorAuthenticationDelete.html
Object Locking to prevent deletion
Object locking as a feature creates read only objects upon upload. With S3 Object Lock, you can store objects using a write-once-read-many (WORM) model. Object Lock can help prevent objects from being deleted or overwritten for a fixed amount of time or indefinitely. You can use Object Lock to help meet regulatory requirements that require WORM storage, or to simply add another layer of protection against object changes and deletion.
From the AWS console or command line, you can only enable Object Lock on new buckets. To enable Object Lock on a bucket that is already created, you will need to reach out to Customer Support.
Instructions to enable Object Locking for new buckets is available here - https://docs.aws.amazon.com/AmazonS3/latest/userguide/object-lock.html
Conclusion
Data is the primary property for a lot of organizations. This could be data that is produced as part of services that organizations offer, data that is used to set up and run the business, intellectual property that allows for product and service creation, customer data that is processed and stored, financial, medical or any other category. It is therefore of paramount importance to protect and store data.
AWS S3 provides a host of security features that when enabled and configured properly, allow the data to be created, stored, managed, processed and archived securely. Ensuring the security of data throughout its lifecycle enables businesses to run smoothly and provides assurance to customers and users alike.
References
- https://docs.aws.amazon.com/AmazonS3/latest/userguide/access-control-block-public-access.html
- https://docs.aws.amazon.com/AmazonS3/latest/userguide/example-bucket-policies.html#example-bucket-policies-use-case-3
- https://docs.aws.amazon.com/AmazonS3/latest/userguide/ShareObjectPreSignedURL.html
- https://docs.aws.amazon.com/console/s3/bucket-encryption
- https://docs.aws.amazon.com/console/s3/server-access-logging
- https://docs.aws.amazon.com/console/s3/enable-bucket-versioning
- https://docs.aws.amazon.com/console/s3/object-lock
This article is brought to you by Kloudle Academy, a free e-resource compilation, created and curated by Kloudle. Kloudle is a cloud security management platform that uses the power of automation and simplifies human requirements in cloud security. Receive alerts for Academy by subscribing here.
